
2022 회고 (2/3): 컴퓨터공학과 학생의 졸업작품, Bookstamp
CYAN4S가 속한 팀 Chocolatte의 졸업작인 도서 커뮤니티 Bookstamp에 대한 이야기이다. Next.js, Firebase 기반의 웹앱과, TensorFlow 기반의 추천 AI를 개발하는 과정이 담겼다.
이번 편에서는 내가 속한 팀인 Chocolatte에서 만든 도서 커뮤니티 Bookstamp와 관련된 이야기를 해보려고 한다. Bookstamp는 Next.js 기반의 웹 커뮤니티로, 나의 학부 졸업작품이기도 하다.
프로젝트 기획, 그리고 탄생한 도서 커뮤니티
2021년 여름, 3학년 2학기 개강을 기다리는 중이었다. 학과 게시판에 창의설계프로젝트기획 수업으로 팀을 구성하라는 공지가 떴다는 소식을 동기가 알려주었다. 창의설계프로젝트기획은, 3인 팀을 구성하여 한 학기동안 프로그램을 하나 기획하는 수업으로, 졸업작품을 위해 의무적으로 수강해야 했다. 이미 팀을 이룬 친한 동기 두 명이 팀 합류 제안을 했고, 그대로 팀에 합류하게 되었다.
먼저 한 학기동안 기획할 주제를 생각해야 했다. 팀원과의 브레인스토밍을 통해 생각해낸 아이디어는 총 9개였는데, 10개의 아이디어를 무조건 내야 했다. 참고로 이 때 내가 낸 아이디어에서 지금 기억나는 것은 ‘생산성 향상을 위한 타이머’, ‘스마트 짐볼’ 등이 있다.
추가적인 아이디어를 곰곰히 생각하던 도중, 바로 내 앞의 책장에 있던 책들이 눈에 띄었다. 평소 책으로 공부하던 나는 책에 있는 정보들이 금방 노후화될 것을 염려하여, 책과 관련된 커뮤니티를 만들어 정보의 장을 만들면 어떨까 팀원들에게 얘기를 했다. 이 아이디어는 사실 수를 늘리기 위해 즉석으로 생각해 낸 것이었다.
이후 10개의 아이디어 중 어떤 아이디어를 기획할 지 선택하는 단계가 왔다. 개인적으로 ‘스마트 짐볼’의 아이디어가 괜찮았지만, 막상 실물을 만들려면 라즈베리파이나 아두이노 같은 임베디드 시스템까지 다뤄야 해서 개발 부담이 컸다. 이렇게 괜찮았던 아이디어들이 현실성을 이유로 폐기되었고, 얼떨결에 도서 커뮤니티가 선정되었다.
주제가 선정된 후, 이제는 기획할 커뮤니티를 구체화할 차례였고, 이를 위해 회의가 진행되었다. 하지만 다들 아이디어는 있지만, 서로의 아이디어를 말로 설명하려 하니 서로 이해하지 못하는 상황이 벌어졌다. 그렇게 회의를 계속 짧게 끝내고 싶어도 회의는 끝없이 길어졌다.
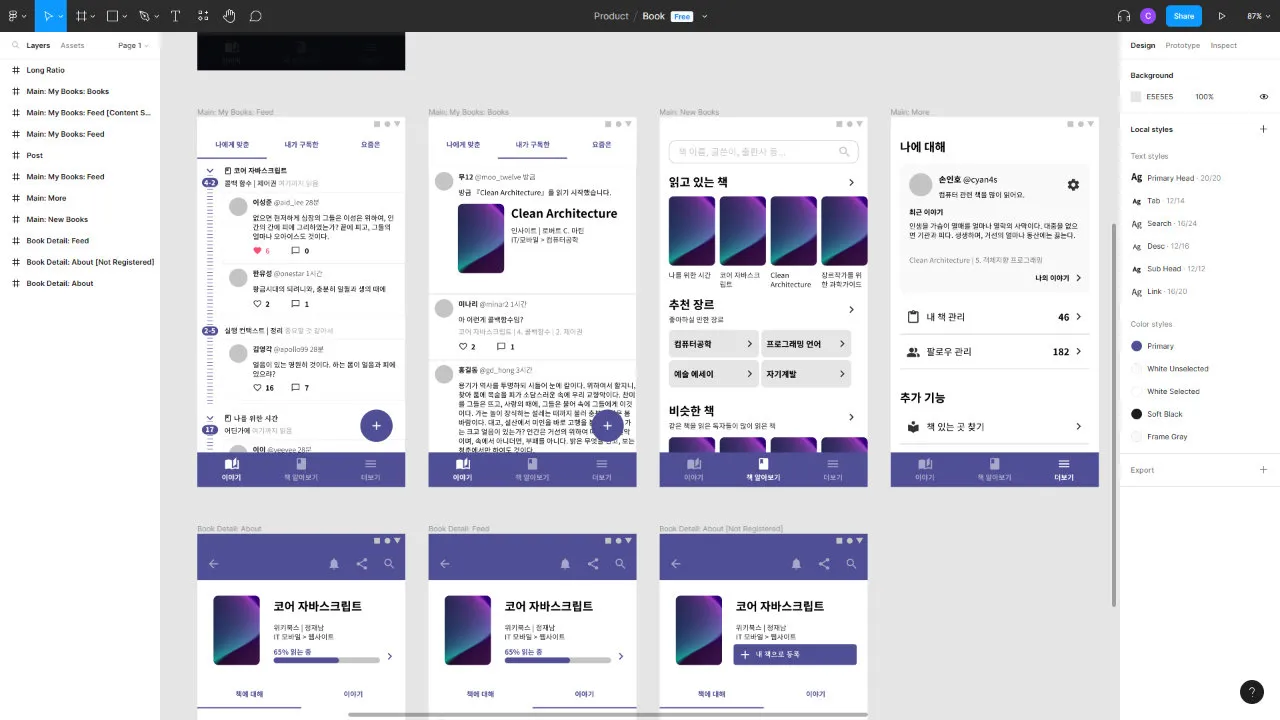
계속 이렇게 이어지면 평생 회의가 끝나지 않을 것만 같았다. 내 아이디어를 백 번 말로 하는 것보단, 차라리 한 번 그림으로 보여주는게 나을 것 같았다. 그래서 난 회의를 강제로 중단시키고, 그날 밤새 Figma를 사용해 프로토타입 UI를 모두 설계하였다. 그리고 이를 회의에 활용하여, 기획을 이어나갈 수 있었다.
(참고로 위 사진에 있는 프로토타입 화면을 수업에서 발표할 때 참고 이미지로 넣었는데, 담당교수님이 실제 서비스 중인 앱으로 착각하시는 해프닝이 있기도 했다.)
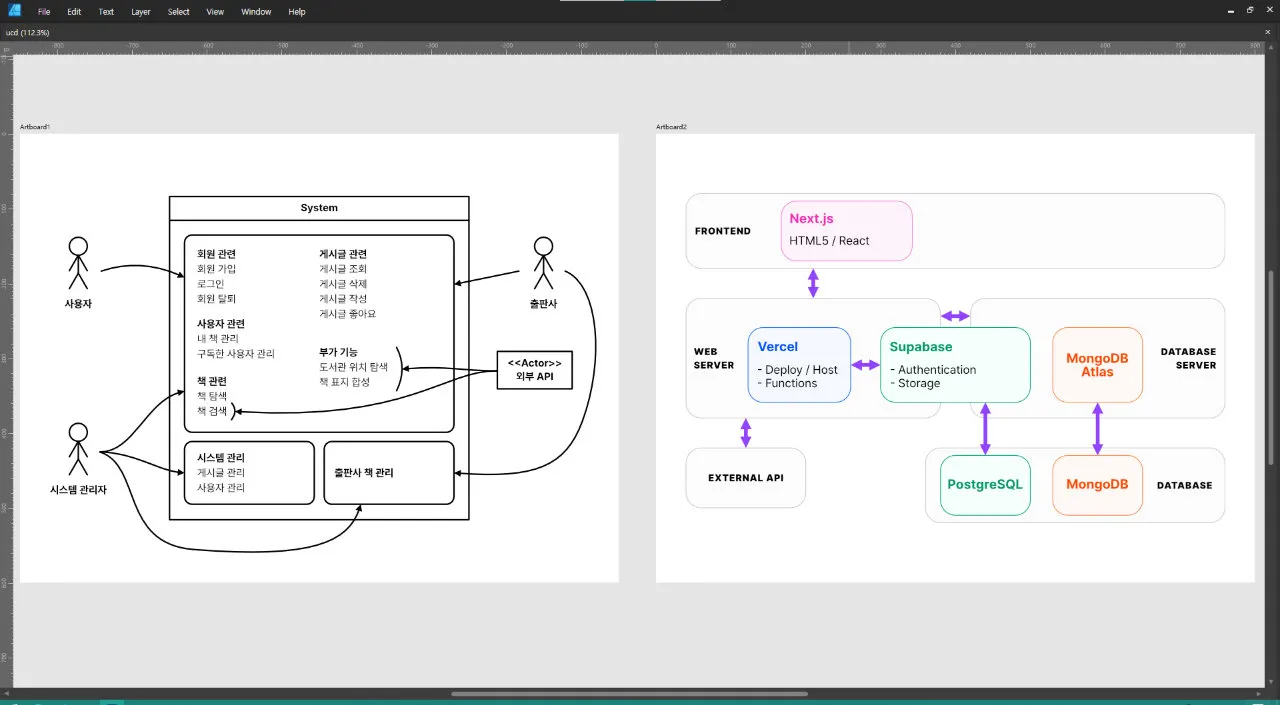
이후, 수업 진행에 따라 소프트웨어 기획서를 완성해갔다. 이 과정에서 유즈케이스 다이어그램, 시퀀스 다이어그램, 클래스 다이어그램 등 웬만한 다이어그램은 다 만든 것 같았다. (위의 사진 오른쪽은 기술 스택 구성도인데, 실제 구현에선 기술 스택이 다소 변경되었다. 이유는 곧 서술한다.)
그리고 이 기획은, 이어질 이야기인 Bookstamp의 시작이 되었다.
졸업작이 된 도서 커뮤니티, Bookstamp
그리고 4학년이 찾아왔다. 이제 전 학기에 기획한 도서 커뮤니티를 실제로 제작해야 하며, 이 과정에서 방향성 문제로 인해 팀원 한 명이 교체되었다.
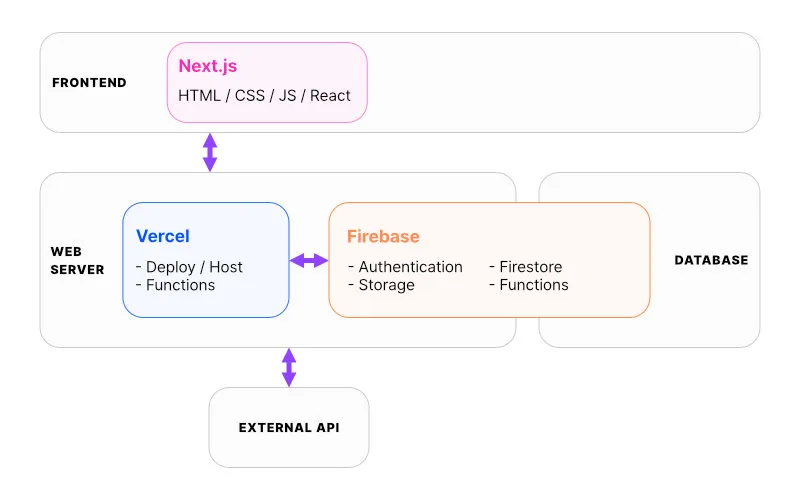
개강 전에 회의를 통해 기술 스택을 정하였고, 원활한 개발 진행을 위해 개강 전까지 Next.js와 Firebase를 공부해오기로 했다. 이 당시엔 스마트폰 앱 개발 또한 고려하여 Flutter를 추가로 배웠지만, 웹앱 개발만으로 벅차다는 판단으로 무산되었다. 지금 생각해도 매우 현명한 선택이였다.

이후 프로젝트 이름이 Bookstamp로 정해졌다. 로고는 내가 만든 것인데, 책갈피가 꽂힌 책의 측면, 그리고 일반적인 원형 스탬프 마크 모양을 융합한 디자인이다. (참고로 주 색상은 #6435C9의 보라색, 폰트는 Raleway다.)
Next.js
웹앱 개발은 Next.js로 이루어졌다. Next.js는 이미 전 학기의 기획 단계에서 선택된, 예전부터 사용이 확정된 프레임워크였다. 이 때 당시엔 Next.js 의외의 선택지를 상상하기 힘들었고, 사실 지금도 개인 작업이 아닌 팀 작업이면 무조건 참고 리소스가 많은 Next.js를 선택할 것이다.
Next.js의 존재는 이미 예전부터 알고 있었다. 공부하는 겸 블로그에 Next.js를 요약한 글을 쓴 적이 있을 만큼, Next.js를 어떤 방식으로 사용할 수 있는지는 알고 있었다. Next.js가 대강 어떤 방식으로 작동하는지 알고 있던 나는, 팀원들에게 Next.js 사용을 적극 권장하였다. 팀원들 모두 이미 React를 사용해 본 경험이 있어, 금방 개발이 이루어질 수 있었다.
여담으로, Next.js 사용법을 검색할 때마다 내 블로그 게시물이 나와서 기뻤다. 팀원들도 Next.js를 검색할 때마다 내가 쓴 게시글이 나와서 놀랐다고.
Recoil
개발 도중, 사용자 정보와 관련하여 앱이 이상하게 작동하는 부분이 생겼다. 사용자의 정보가 바뀔 때 화면에 표시되는 정보가 즉각적으로 변하지 않는 문제가 발생한 것이다.
Auth와 같은 전역 정보는 다른 방식으로 관리해야 했다. 처음에는 React에 내장된 Context API를 사용하려 했지만, 기능이 빈약하고 사용이 불편했다.
문제 해결을 위해 React의 생태계를 조사했고, 이 때 React 상태 관리를 위한 라이브러리들의 존재를 알게 되었다. 심지어 이와 관련된 정보의 규모가 상당히 크게 형성되어 있다는 것에 놀랐다. 지금도 마찬가지지만, 웹 개발은 배워야 할 기술이 금방 발전한다는 것을 그 때에도 느끼게 되었다.
상태 관리가 정확히 무엇인지 조사하고, 프로젝트의 방향성에 맞는 라이브러리를 선택하기 위해 노력했다.
초기에는 대중적인 Redux를 고려했지만, 상당히 배워야 할 것이 많아 부담이 컸다. 라이브러리 하나 때문에 많은 것을 추가로 배우는 것은 부담이 크기에, 부담이 없으면서 프로젝트에 분명한 이점을 줄 수 있는 라이브러리를 찾았다.
그 결과, React의 개발 팀이기도 한 Facebook에서 만들었고, 꽤나 부담없이 사용할 수 있는 Recoil을 도입했다. Recoil의 주요 개념인 Atom, Selector는 쉽게 익힐 수 있었으며, 사용법 또한 친숙하여 앱 내에 빠르게 적용할 수 있었다.
React Hooks
개발 도중, 이미지 선택 기능을 위한 로직이 여러 곳에서 중복되어 있다는 것을 알게 되었고, 로직을 최대한 편한 방식으로 재사용 가능하게 리팩토링을 하고 싶었다. 그러던 중, 사용자 정의 Hook이라는 개념을 알게 되었다.
이후 이미지를 선택할 때 사용하기 편한 Hook을 제작하여 사용하였다. 그리고 나름대로 JSDoc을 이용해 다른 팀원들이 사용하기 편하게 설명을 달아놨다. 실제로 도움이 됐는지는 모르지만…
Firebase
초기에는 Supabase를 사용할 예정이었다. 전 학기의 기획에서 SQL을 사용한다는 전제하에, 대략적인 SQL 스키마를 설계했다. 그리고 이를 활용하기 위해, Supabase 내장 DB인 PostgreSQL 사용할 예정이었다.
하지만 이 때 당시에 Supabase는 아직 한창 떠오르는 시기여서, 개발 시 참고할 만한 리소스가 많지 않았다. 리소스가 적다는 말은, 개발에 문제가 생겼을 경우 해결이 매우 늦춰지거나, 해결이 불가능할 수도 있다는 말이다. 혼자서 하는 프로젝트라면 이런 리스크를 혼자서 짊으면 되지만, 아무래도 팀 프로젝트다 보니 선뜻 유명하지 않은 서비스를 도입하는 것은 무리였다.
따라서 대중성이 높은 Firebase를 도입하는 것으로 선회하였다. 데이터베이스의 경우 자연스럽게 Firebase 내장 DB인 Firestore를 사용한다. Firestore는 문서형 DB로, 전에 같은 문서형 DB인 MongoDB를 다뤄본 적이 있어 적응이 어렵지는 않았다. 다만 전에 설계했던 SQL 스키마를 사용하지 못했다는 점은 아쉬웠다.
2020년 회고록에서 언급한 적이 있었는데, Firebase와 React를 통해 빠르게 채팅 앱을 만든 적이 있어 기본적인 Firebase의 사용 방법을 알고 있었다. 그래서 팀원들에게 Firebase를 적극적으로 추천할 수 있었다.
그리고… TensorFlow
인공지능과 관련하여 틀린 서술이 있을 수도 있습니다! 해당 글을 지식 습득을 위해 사용하는 것은 권장되지 않습니다.
프로젝트 개발이 어느정도 방향성을 잡아, 순조롭게 진행되던 때였다. 프로젝트에 무언가 차별점이 있어야 할 것 같다는 생각에 딥러닝 기반의 도서 추천 시스템을 넣기로 하였다. 기획 단계에서 어필 요소로만 넣은 기능을 실제로 구현하려 했다.
그리고 이는 지금 생각해봐도 미친 결정이었다.
딥러닝을 통한 추천 시스템을 개발하기 위해 여러 자료를 알아보다가 TensorFlow Recommenders(TFRS)를 발견해서, 이를 그대로 활용하였다. TensorFlow는 바로 작년인 3학년 내내 다뤄봤던 도구고, TFRS는 TensorFlow에서 직접 만든 모델이기도 하니, 별 걱정없이 이를 사용하여 인공지능을 쉽게 만들 수 있을거라 생각했었다.
딥러닝 활용 계획
딥러닝을 활용하여 어떤 기능을 넣을 수 있을지 고민을 하였고, 여러 아이디어가 나왔다. 그 당시 포부는 컸다. 이 때 무슨 계획까지 세웠나면,
- 특정 책을 선택하면, 그 책과 관련된 책들을 추천해주는 기능을 구현한다. 이를 위해, 특정 책에 대한 관련 책의 (질의, 후보) 쌍 형태의 데이터들을 수집해 모델에 학습시킨다.
- 이후 책의 특징(카테고리, 주제 등)을 활용해, 학습에 활용되지 않은 새로운 책에 대해서도 높은 성능을 낼 수 있도록 한다.
- 사용자가 관심있어 하는 책을 기반으로, 관심사에 맞는 책을 추천하는 기능을 구현한다.
- 사용자로부터 데이터를 수집하여 뭐든 해본다.(…)
후술하겠지만, 정작 이뤄진 건 첫번째 항목 뿐이다. 이마저도 제대로 작동한다고 보기도 어렵고.
학습 데이터 수집
먼저 도서 관련 API 사용과 웹 크롤링을 통해 데이터를 가져와, 이를 학습 데이터에 적합한 형태로 가공하는 것이 첫번째 업무였다. 이 과정에만 한나절이 걸렸다.
데이터 수집 및 가공에는 TypeScript를 사용했다. 가공 결과를 바로 확인할 수 있게, Node.js라는 REPL 환경이 잘 되어있는 언어를 선택하였다.
Node.js 콘솔에서 바로 실행 가능한 JS를 두고 TS를 고른 이유는, 타입 시스템의 존재 때문이었다. 온갖 곳에서 자료를 수집하다 보니 데이터 형식이 뒤죽박죽이였고, 이를 잘 관리하기 위해 타입 시스템이 필요했다. 컴파일 과정이 필요하지만 타입 시스템의 편의성이 매우 컸고, 애초에 코드 규모가 큰 건 아니라서 부담이 없었다.
나에게 가장 익숙한 C#을 사용해볼까 생각은 했지만, REPL 사용이 까다로워 포기했다.
최종적으로, 9734권의 책들 사이 [질의 책, 후보 책] 형태의 관련 쌍 26544개를 구하였고, 이를 JSON 파일로 만들어 다음 단계인 모델 학습에 사용될 수 있게 하였다.
여담으로, 책의 특징이 활용될 수 있게 모델이 확장될 것을 대비해, 책의 특징의 될 수 있는 정보도 별도로 저장해 두긴 했다. 뭐, 지금으로선 의미 없는 행동이긴 하지만.
모델 구조 설계, 학습 및 테스트
이후, 공식 튜토리얼 사이트와 공식 유튜브 튜토리얼에만 의존한 체, 추천자 시스템이 뭐하는 물건인지를 배우며 개발을 이어나갔다.
단어 하나하나가 생소했고, 심지어 다 영어다. 기계 번역된 한국어 문서는 도저히 눈 뜨고는 볼 수 없는 수준이었기에, 영어 원문을 울면서 읽어야만 했다. 이 때 반강제로 영어 실력이 늘었다.(…)
그래도 대충 구조가 파악이 된 후에는, 뭔가라도 작성해서 실행해보았다. 진전이 보일 때마다 환호성을 질렀고, 에러가 날 때마다 울었다. 그렇게 울고 웃고를 몇 날 며칠 반복하였다.
심지어 Python이 그리 익숙하진 않은 나는, 알 수 없는 긴 에러 메세지를 해독하기 위해 머리를 쥐어짜야했다.
내가 딥러닝에서 허덕이는 사이, 다른 팀원들은 Next.js 앱 개발을 계속 이어나가 프로젝트가 거대하게 성장했다.
다른 팀원들이 착실히 앱의 규모를 키우는 와중에도, 나는 종종 진행되는 회의에서 아직 성과가 없다는 말 밖에 나오지 못했다. 팀원들은 풀이죽은 나를 진심으로 다독여주었지만, 그래도 나는 뭔가라도 만들어야 한다는 생각만 머리에 들었다.
여러 시행착오를 겪은 끝에 처음으로 결과가 제대로 된 형태로 나왔을 때, 너무 기뻐서 눈물이 다 나왔다. 소리를 지르며 방 안을 뛰어다녔을 정도.
최종적으로, 특정 책에 대해 관련된 책 10권을 추천하는 인공지능을 만들었다.
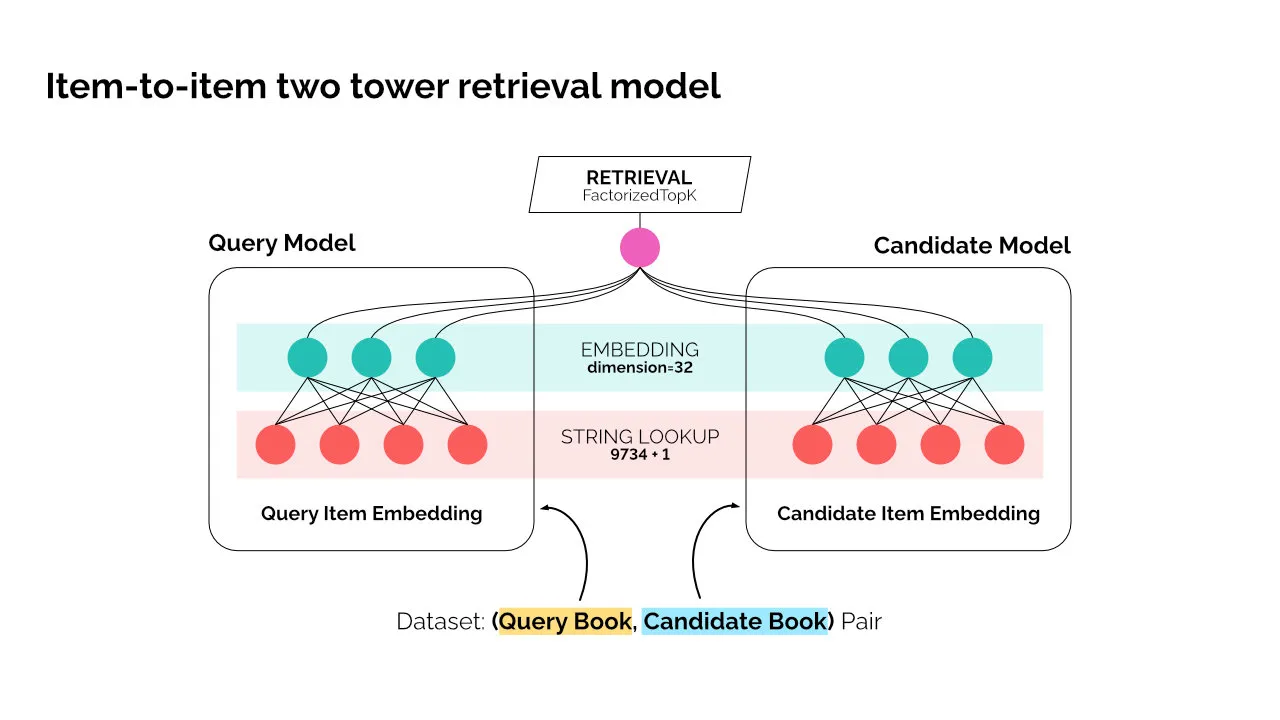
Two-tower Retrieval 모델이며, 모델의 상세 구조는 다음과 같다.
- 모델 구조: 2개의 서브모델을 가진 Retrieval 모델
- 질의 모델: Sequential
- StringLookUp
- 32차원 Embedding
- 후보 모델: Sequential
- StringLookUp
- 32차원 Embedding
- 질의 모델: Sequential
- 평가 지표:
tfrs.metrics.FactorizedTopK - 손실 함수:
tfrs.tasks.Retrieval - 학습 방법: Adagrad
- Learning rate: 0.1
- 예측 수행:
tfrs.layers.factorized_top_k.BruteForce
뭔가 거창하게 적어놨지만, 사실 공식 튜토리얼에 소개된 모델을 그대로 가져와서 조금 손을 본 것에 불과하다. 솔직히, 나도 지금 이게 뭔지 모른다.(…)
지금 생각해보면 모든 과정이 굉장히 야매였다. 실제로 추천을 돌려보면 연관성이 없어보이는 책이 섞여서 나온다. 성능 평가? 어떻게 해야 하는지도 모르겠다…
모델 배포 및 앱 내 활용
완성도가 처참해도 어쨌든 작동은 하니, 앱에서 활용할 수 있도록 모델을 클라우드에 넣어야 했다. 이 때 떠오른 아이디어는,
- TensorFlow를 구동해 ML 모델을 실행시키는 Python 코드를 서버리스 함수로 배포
- ML 모델을 지원하는 머신러닝에 특화된 클라우드 서비스에 배포
그런데, Firebase Functions는 JavaScript만 받고, Firebase ML은 네이티브 모바일 앱 환경에서만 구동이 된다. 하는 수 없이 Python 함수를 지원하는 다른 클라우드 서비스를 찾아야 했다.
이 때 선택한 곳이 Google Cloud였다. 그런데, 애초에 Firebase가 Google Cloud 기반이다보니 서로 연결이 편했다. 게다가 함수를 Google Cloud에 넣었더니 Firebase에서 관리가 가능했다.(…) 심지어 모델 데이터는 Firebase Storage에 저장했다.(……) 둘이 뭐 어떻게 연결이 되어있는지 이젠 감도 안 잡힌다…
참고로 TensorFlow.js를 활용해 JS 기반으로 만들기를 도전해보았지만, 뭔가 계속 꼬이는 바람에 실패했다.
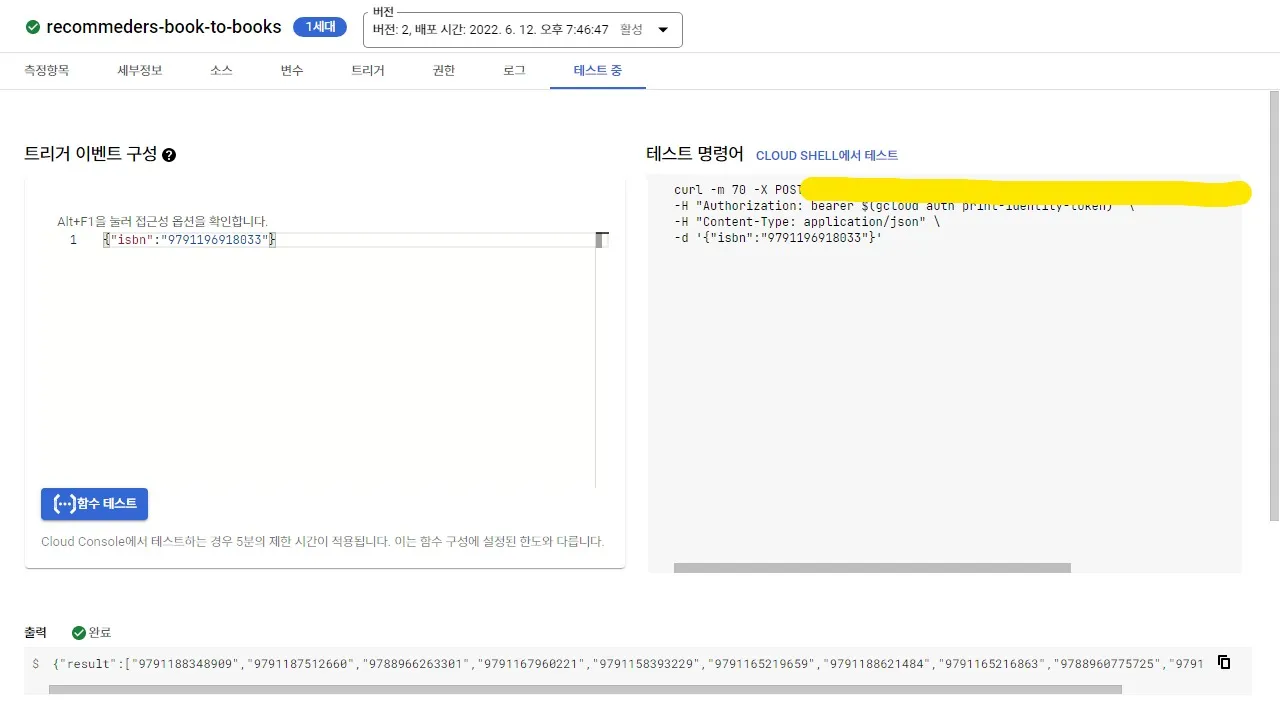
이후, 이 함수를 API처럼 사용할 수 있게 입출력 형태를 정의했고, 다른 팀원이 이를 활용하여 Next.js 앱에 추천 책 목록를 표시하였다.
끝내, 앱 내에 추천 시스템을 넣었다. 작동은 하는. 지금 이게 어떤 원리인지 설명하라고 하면 자신이 없다. 이를 구동하는 함수는 아직도 클라우드에 있으며, 이로 인해 지금도 매달 200원 가량의 돈이 클라우드 비용으로 빠져나간다.(…)
만약 딥러닝 관련 소스 코드를 보고 싶다면… 여기에 있다. (뭐하는 코드인지 알려고 하지 말자. 나도 잘 모른다…) 그 많은 일이 있었음에도, 아직도 Python이 생소하게 느껴진다. 자주 다루는 언어가 아니라서 그런지 더욱 어색하다.
지금 보면, 이 짧은 코드를 작성하기 위해 몇 달을 태웠다는 사실이… 허망하다.
그리고…
솔직히 말하자면, 이번 프로젝트에서 내 기여도는 많지 않은 편이다. 오히려 종종 회의에서 빠지는 등, 팀에 민폐가 되는 행동을 했다. 지금 생각해도, 팀원들에게 너무 미안하다…
이 프로젝트를 기점으로 몸이 본격적으로 안 좋아졌고, 정신 건강은 더욱 처참히 무너졌다. 팀원들은 모두 한마음 한뜻으로, “역시 프로젝트는 사람을 망가뜨린다.”라는 말이 나왔다.
이후, 이 프로젝트는 학교 박람회인 2022 kit Engineering Fair에 출전이 되었다. 우리 팀은 팀장이 우리 팀 부스의 자리를 지켰으며, 이 박람회에서 동상을 수상했다. 팀장의 말로는, 프로젝트에 딥러닝 추천 시스템이 있다하니 관심을 더 잘 끌었다는데… 내가 박람회에 있던 것은 아니라서 잘 모르겠다.
새 단장을 목표로 컨셉 UI를 만들었지만, 실제 구현으로 이어지지 않았다. 프로젝트가 끝나면서, 유지보수할 의지가 사라졌기 때문이다.
게임 업계를 선망하는 나에겐 이 프로젝트는, 뭐랄까, 다소 나와는 맞지 않았다. 물론 웹이나 인공지능 개발이 게임 개발에 아예 도움이 안 된다는 말은 아니다. 하지만 이 때 당시만 해도 게임 쪽 포트폴리오가 부실한 상황이었기에, 프로젝트를 진행하면서도 게임 관련 포트폴리오를 만들지 못하면 어떡하나 마음이 조급해졌다.
그래서, 다음 학기에는 정말 게임 개발에만 집중해야겠다 마음을 먹었다.
Next,
2022 회고록 시리즈의 마지막이 될, 다음 편에서는 4학년 2학기에 참여한 게임 행사, 그리고 그동안 만들어온 각종 작업물을 소개할 예정이다. 다음 편이 이 시리즈에서 가장 재미있는 편일 것 같다.